How to Use Wayback Machine
The Wayback Machine is a search engine in the world of the internet that is used to archive blog posts and webpages, work as a backup in time of needs and give information that has been lost with time. It is the simple solution for anyone who needs to find out the back history of a particular website or how it looked like from the past to the present. For this, one needs to know how to use the Wayback Machine properly.
Using this digital archive has become quite easy over time with the development of technology. Internet Archive, the founders of the Wayback Machine gave publicly free access to everyone in 2001 for a greater purpose. From then, anyone can search contents, archive webpages, find lost websites, and download content from this search engine.
How Does It Work
The Wayback Machine, a digital record room for the world of internet, mainly archives webpages by using some spidering or web crawling software. Though it already archives more than 431 billion pages that don’t mean everything gets permission to be archived in this program. The archiving process goes through some specific criteria.
The web crawling software gives permission which domain is allowed to archived. When the software does not permit any domain to enter, there shows a “no crawl” message rather its archive snapshots. If the domain is allowed, then the contents of that domain are indexed and recovered and thus archived as a webpage. Moreover, if the owner wants, he can remove his websites from the Wayback Machine.
Mainly, contents of websites are archived as HTML files or snapshots or related external files like image files. The Wayback Machine cannot understand other programming languages as it can extract contents only written in HTML. Again, chat or email websites don’t get permission to get archived because of the security issue and password protected sites are not accessible for the public.
How to Use the Wayback Machine
How to Search in the Wayback Machine
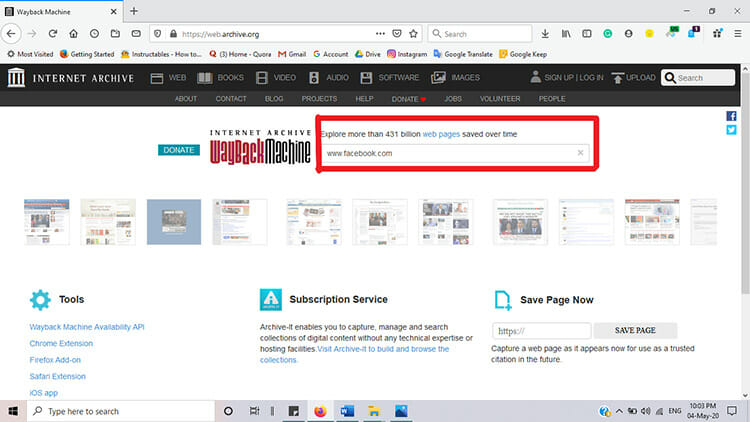
The Wayback Machine is mostly used as a search engine as people use it for research work, verification of news, website contents, and blog posts. Go to the search engine of your web browser and type ”https://web.archive.org” into the text box. This is the URL of the Wayback machine by Internet Archive.

After opening the webpage of the Wayback machine, you will find a search box labeled “Enter a URL or words related to a site’s homepage.” Here you can type the full address of the webpage you want to see or any keyword or name of the website.
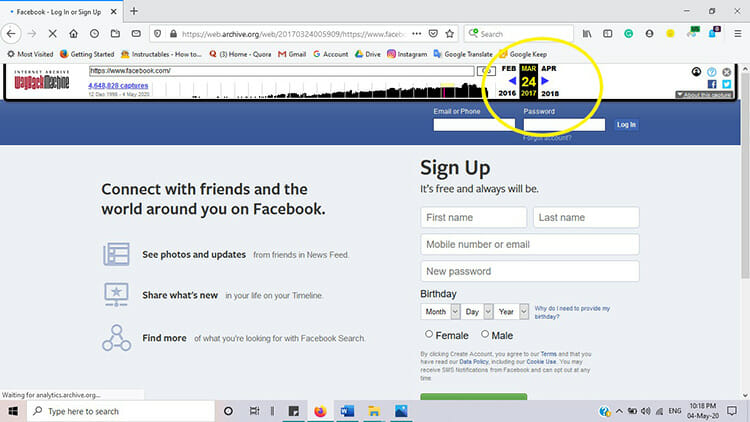
Suppose, if you want to see the change of the website ‘Facebook’ over the time, you simply need to type the URL ”https://www.facebook.com” in the search box or we can type only ‘Facebook’. If you search only by ‘Facebook, you’ll see a list of suggested sites. You can select the URL of the website and then proceed to the next step.
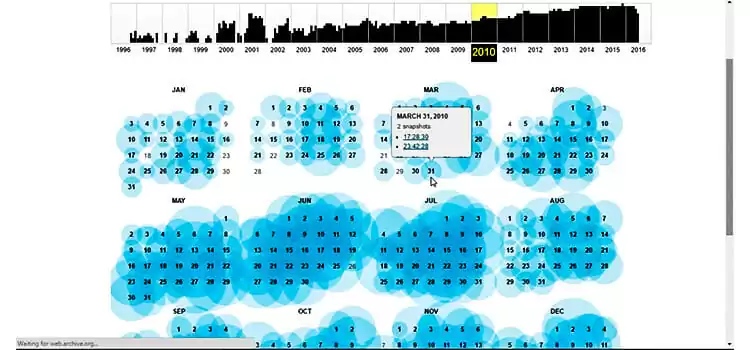
Then, the webpage will show a bar graph of years and calendar. From the bar graph of years, you can choose the year in which you want to see how the webpage of ‘Facebook’ looked like. After selecting an area of any year, a calendar of 12 months showing each date of that year will appear on the screen which will help you to choose the date.

From the bar graph, you will notice that the Wayback Machine can show you the webpage of ‘Facebook’ till today’s date. The black bars indicate the number of archived pages by this tool during that year. No black bar means no website snapshots were captured on that year.
In the calendar, you will see some of the calendar dates are circled by blue or green colour which means snapshots of that site are available from that date. When you keep your cursor on any date, you will see the list of the archived version of the website.

The bigger blue circles mean the number of snapshots is more comparing with the smaller blue circle and the green circles indicate the lowest number of archived snapshots.
From the bar graph, you can jump on the previous or next archived snapshot of that website by using the blue arrows. The web pages display on the Wayback Machine as if they are running today.
How to Archive/Save/Capture Webpages on the Wayback Machine
The Wayback Machine can archive webpages both automatically or manually. In the bottom-right portion of the page, you will notice the “Save Page Now” field. You can simply type the URL in that toolbox and click the “Save Page” button or you can visit the “Save Page Now” page by typing ”https://web.archive.org/save “ separately.
On the “Save Page Now” page you will notice some options which will help you to save your contents manually. If you want to save webpages with active links on that page, check the “Save outlinks” option. If webpages return an HTTP status code error, check “Save error pages (HTTP Status=4xx, 5xx)” option.
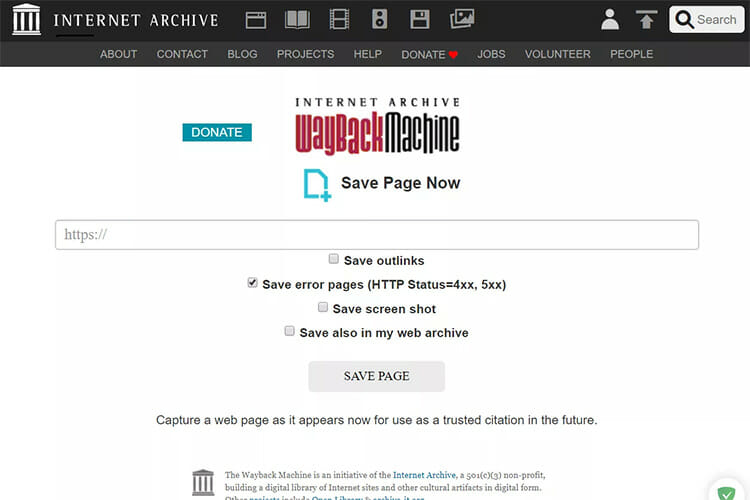
You can archive image versions of webpages by choosing “Save screenshots option and if you have an account on the Internet Archive’s website, you will also get an option called “Save also in my web archive” which archives pages in your account to see later.
You must be careful when typing URL to archive webpages because the Wayback machine archives one webpage at a time, not the whole website or other linked pages. You have to enter the full address of the webpage which you want to archive.
How to Access Archived Contents
When you archive a webpage, the process may take some time based on the size of the page. You will get a direct URL of your archived page which you can copy and save to get access directly later. But, you may not able to access your page immediately as it can take some days to get fully archived.
You can find your archived content by using the full address of your page on the Wayback Machine just like the other search on that. You also can use the main web address or just the link to the webpage unless you forget the full URL of your page. The search engine will show you all the related results of the address you want to search for.
How to Recover a Website
In case you lost your archived contents or forget the full address, you can follow some rules to recover it fully. Advantageously, the Wayback Machine takes snapshots of websites automatically, so your sites may also be captured, but it is recommended to keep backups regularly of your website.
Simply, visit the “Browse History” option as it keeps the history of how many times your site was saved over a while. You can also check the date on the calendar to view saved snapshots on that date. Once you find out, you can recover your site from the search engine.
How to Download Contents From the Wayback Machine
To download any websites or contents from any webpage of the Wayback Machine, you need to use a third-party service like Wayback Downloader, Wayback Machine Downloader, etc. If you are using Wayback Machine Downloader to download content, it is necessary to know the process of how to download from the archive correctly.
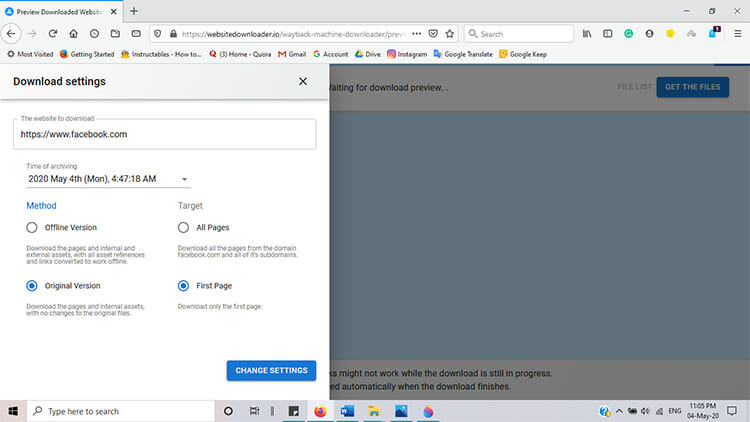
In the Wayback Machine Downloader page, you will find a search box where you must give the correct URL with the exact date from the Wayback Machine which you want to download. After sometimes, a file will be sent to your email address from which you can download archive files. For this, you need to have an account on this site.
If you don’t choose the exact date, you will preview with a page in which you have to give the date information. Sometimes that doesn’t work properly, so it’s better to type address selected with date from the Wayback Machine to get better results.
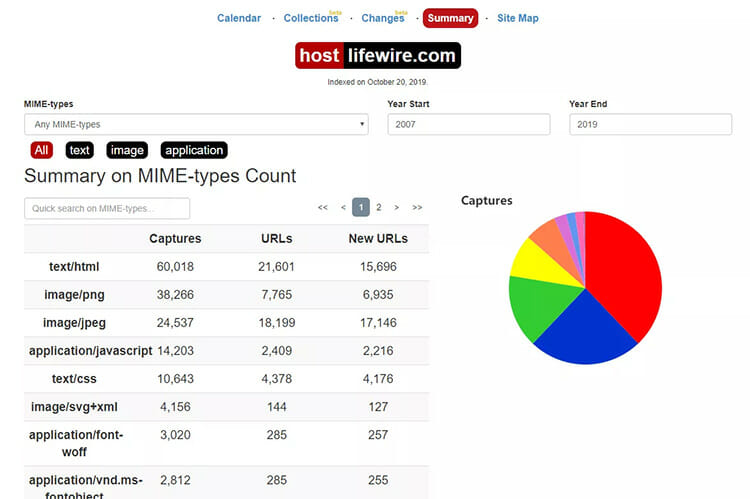
How to See a Summary of a Website
When you search for a website on the Wayback Machine, you will see a “Summary” section beside the “Calendar” option which will help you to see the overall summary of the website. This section shows the summary of several HTML files, image files, text files, applications, and various documents between any two years that you want to see. You have to insert two years in the “Year Start” and “Year-End”.
Source: https://www.lifewire.com/wayback-machine-3481829
Some Tips for Better Use
To use this tool more easily, there are many extensions and plugins available in your web browser. Wayback Machine has extensions for Chrome and Firefox browsers like many other browser extensions, for example, Ginger, OneTab, etc. for bloggers. These Wayback machine extensions can easily save your page with one click, sometimes archive automatically and you can also visit the pages of the archiver with these extensions.
Besides these extensions, there are many third-party services like Wayback Downloader, Wayback Machine Downloader, ArchiveScraper, etc. which can easily save your time when using the Wayback Machine. They help to scrape and recover websites, download contents, and webpages from the machine.
Conclusion
This virtual time traveler helps you to explore the webpages no longer available to the public, archive your sites for future and work as a backup in times of need. You can browse over 431 billion webpages which were archived since 1996 and for this, you need to know the using process. Hopefully, this article will help you to figure out how to use Wayback Machine efficiently.
How a particular website changes frequently over time can be observed with the Wayback Machine, as it archives many well-known websites for many years. This digital archive will help you a lot in your research work as it stores closed websites, old information, and website contents. But, if you are facing any problems to search any posts or webpages, archive them for future or maybe troubles to download or restore your previously archived content, this article can guide you to deal with your problems.
Subscribe to our newsletter
& plug into
the world of technology